TL;DR
I’ve been building an MVP (minimum viable product—not most valuable player 😄) that integrates large language models (LLMs) into the battery data management process over the past few weeks.
The new workflow consists of two key steps:
- Data sourcing & indexing, and
- Retrieval-augmented generation (RAG), which automatically decides whether to insert new data or update existing records.
Let me show you how it works.
How we used to manage data
Traditionally, data management has been tedious and labor-intensive. From data sourcing and capturing to input and quality checks, each step often requires multiple teams to manage.
Nowadays, news indexing and data engineering can automate much of the sourcing and extraction. Battery and energy asset data are great examples, since most of their sources come from publicly available news wires on the internet.
However, the rest of the workflow still depends on human judgment to decide the next step: should we insert, update, delete, or ignore the data if it's a duplicate or simply irrelevant? These repetitive decisions are often outsourced to external vendors, which introduces several challenges:
- Systemically, the lack of an efficient search engine can lead to duplicate records when the system fails to locate the right one for update or deletion.
- Operationally, vendors can make mistakes. Even with clear guidelines, their decisions can be subjective. A separate QC (quality control) team might help, but its ROI is often low—it doesn’t address the root of the problem, and sometimes just adds friction between teams.
That’s why handing these tasks over to an LLM feels like the missing piece. It helps streamline the entire data management flow and brings us closer to true automation.
The MVP flow
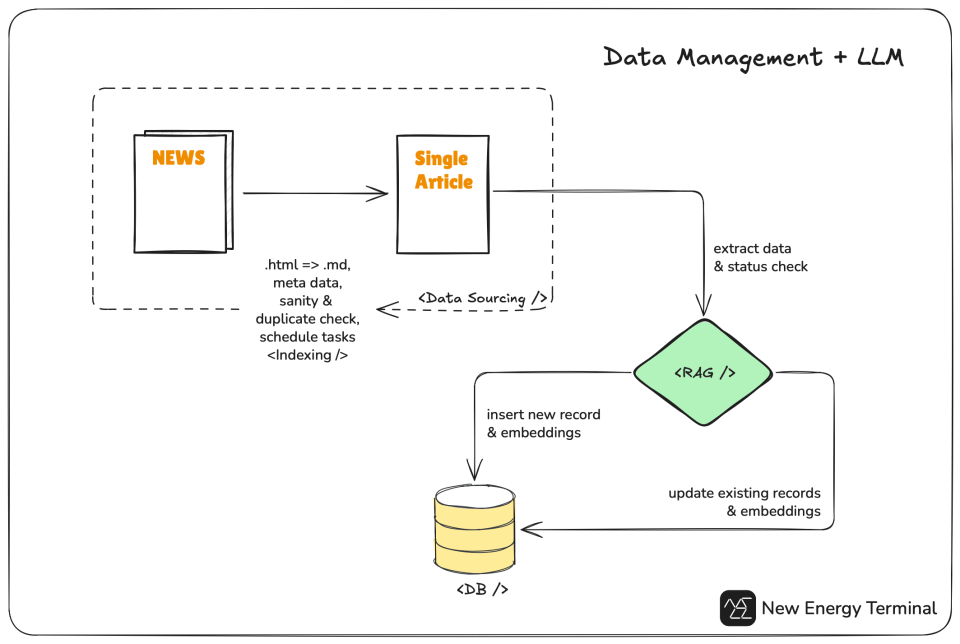
Here’s a high-level overview, introducing two systems: Data sourcing and retrieval-augmented generation (RAG).
Data sourcing runs on an automated news indexing system that processes incoming data on a regular basis. It parses raw content, generates structured metadata, and filters out unqualified information before passing it to the RAG system.
The RAG system manages text embeddings for the metadata of energy assets—such as battery plants, energy storage projects, etc. When new information arrives, it will:
- Generate a temporary embedding of that information
- Search for the most relevant existing asset using vector similarity
- Decide whether to insert a new record or update an existing one, and refresh the associated embeddings accordingly
The architecture includes:
- PGVector as the embedding vector store
- LlamaIndex as the go-to RAG framework
- Ollama for running quantized LLMs and embedding models locally
We also added queues and batch processing to improve efficiency and prevent system overload.
The challenges
As the saying goes: trash in, trash out.
The system depends on effective prompting, high-quality context, and thoughtful role design—all of which act as clear directions and guardrails to reduce the risk of LLM “hallucination”:
- Effective prompting: Clear instructions form the foundation of reliable output.
- Context quality: The strength of RAG is only as good as the quality of the underlying data.
- Role specialization: Instead of assigning one large, multi-task role, it’s often better to split responsibilities into smaller, specialized agents. Each agent handles a single task, and their outputs are chained together—for example, in an agentic data extraction flow (see chart below). Choosing the right LLM for each role is equally important, since different models excel in different domains.

Right now, I’m monitoring outputs while gradually adding more data sources. Even with automation, human oversight is still necessary when things go off track. The RAG system will grow more robust as we continue feeding it cleaner structure and richer context.
That being said, LLMs can be an excellent vendor team—as long as you give them good data and clear instructions to work with.