Over the past few months, I've refactored this app to improve the separation of data, content, and the UI through decoupling, enhancing performance and allowing for more flexible data analyses as it scales.
Additionally, these changes provide greater clarity when interpreting data analyses, along with streamlined user navigation and interaction, leveraging the latest technologies.
Let me walk you through these updates:
Why the updates?
This app was initially built with WordPress, the most popular content management system (CMS) powering over 43% of websites worldwide as of 2024, including Electrive and BNEF.
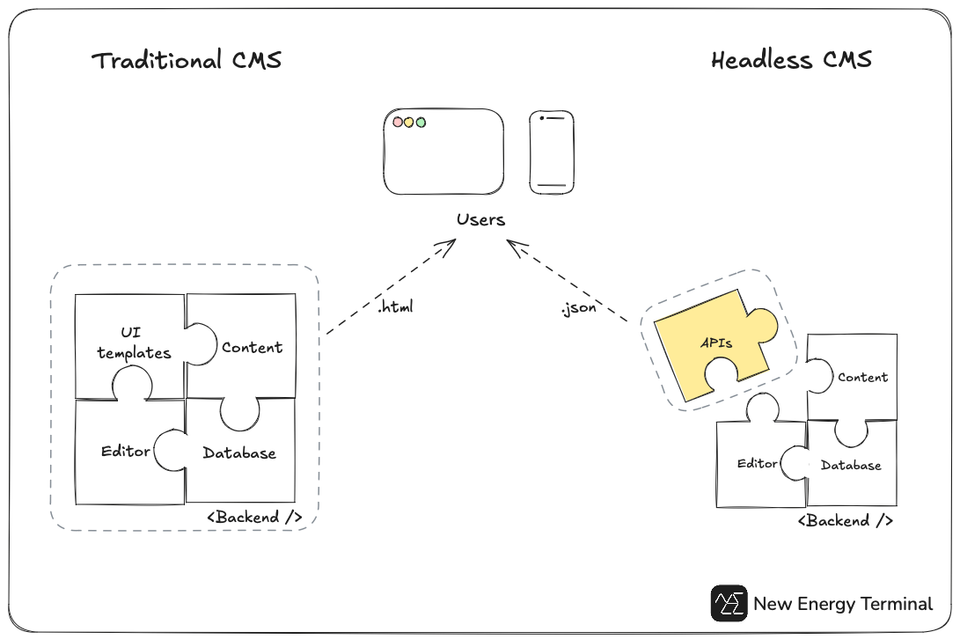
Since early 2023, WordPress has served as my headless CMS, providing REST APIs for the React frontend. However, as the database complexity grew, maintaining it became increasingly challenging due to its tight binding with the WordPress ecosystem.
In August 2024, I started decoupling the database from WordPress. This new stack is designed to handle complex queries and ensure flexibility as we develop additional data and analyses in the future.
The decoupled stack - Q3 2024

The new stack consists of:
- A headless CMS
- A decoupled database
- A meta framework as a handler
Remix (soon to be React Router v7), as a meta framework, elegantly suits my needs without introducing unnecessary complexity. It's lightweight, focuses on web standards and speed. Also, since it's been a layer on top of React Router — which I already used for the old frontend — transitioning to Remix requires fewer code changes compared to other meta framework like Next.js.
I find the new stack efficient and solid, though it comes with both pros and cons:
Pros
- Each component works in isolation, making it easier to test and release updates. This modularity allows us to enrich the data library with more valuable data and analyses.
- The Hybrid SPA + SSR approach improves user experiences by: (a) speeding up initial page loads with server-side rendered (SSR) HTML, and (b) smoothly transitions to a dynamic single-page application (SPA) through hydration.
- While I don’t need server-side rendering during development, I do want a smart backend handler for server-side logic and client-side JavaScript compilation. This streamlines the process, eliminating the need for separate codebases or servers, as is often the case in a traditional frontend and backend separation architecture.
Cons
- Greater flexibility requires more optimization and maintenance compared to a monolithic CMS, which comes with preconfigured caching and security.
- Decoupling stacks often involves mixing and matching various SaaS products, which limits my control over the system.
What's next?

In our next phase, we will focus on improving data coverage and completeness through the automation of:
- Data onboarding and the integration of large language models (LLMs) for tasks such as data mining and validation.
- Regular field-level data quality checks to ensure rationality and identify outliers.
- Searching for data updates based on status changes and their estimated update frequencies.
We will first implement the proposed workflow on battery manufacturing value-chain data. If successful, we will then apply it to renewables deployment data, which are currently paused due to my limited capacity.
Additionally, we will gradually resume the market recap and API sections.
But before we roll out the workflow automation, we invite you to test our new app! You can log in directly with your Google account. If you signed up with a different email, please reset your password — it takes less than a minute.
Your feedback would be invaluable! Also, feel free to join my email list for timely updates!
Thanks!